

前言
我一般从RARBG下载电影,但是,在国内下载BT很慢,使用国外的VPS下载就很快。
于是,我使用VPS下载好电影之后上传到Google Drive,再通过CloudFlare代理拉取电影到本地。
在我家从CF拉取电影可以跑满带宽(axel多线程下载)。
打造“本地EMBY+本地/远端Radarr+远端aria2+Google Drive+CloudFlare”的影视库。
本地和远端VPS默认全为Ubuntu系统。
搭建本地服务
首先安装docker以及docker-compose
curl -fsSL https://get.docker.com | bash -s docker
curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
将下面的内容复制进docker-compose.yaml文件用于搭建本地的EMBY和Radarr,当然你也可以把Radarr搭建在国外的VPS上。注意,根据你的具体情况修改volumes中冒号左侧的本地目录。
#docker-compose.yaml
version: "3"
services:
radarr:
image: linuxserver/radarr:version-4.1.0.6175
container_name: radarr
environment:
- PUID=0
- PGID=0
- TZ=Asia/Shanghai
volumes:
- /root/docker_config/radarr:/config
- /root/downloads:/downloads
- /root/downloads2:/downloads2
- /root/downloads3:/downloads3
ports:
- 7878:7878
restart: unless-stopped
emby:
image: lovechen/embyserver
container_name: emby
environment:
- PUID=0
- PGID=0
- TZ=Asia/Shanghai
volumes:
- /root/docker_config/emby:/config
- /root/downloads:/downloads
- /root/downloads2:/downloads2
- /root/downloads3:/downloads3
ports:
- 8096:8096 # HTTP port
- 8920:8920
- 1900:1900/udp
- 7359:7359/udp
devices:
- /dev/dri:/dev/dri # VAAPI/NVDEC/NVENC render nodes
restart: unless-stopped
运行:
docker-compose -f docker-compose.yaml up -d
搭建VPS远端服务
Rclone挂载网盘
首先,安装rclone挂载Google Drive
apt install rclone -y
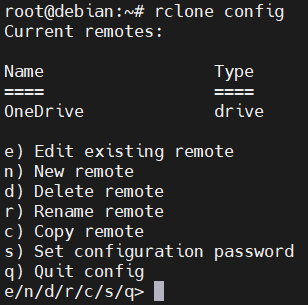
然后,通过rclone config进行配置,记住你给网盘取的名字。我在这里的Name为OneDrive(其实是Google Drive)。
配置Aria2下载器
安装
远端的Aria2采用P3TER的aria2.sh脚本
wget -N git.io/aria2.sh && chmod +x aria2.sh && ./aria2.sh
安装Aria2,并开启自动更新Tracker。安装目录在/root/.aria2c(隐藏目录,前面有个点)
Aria2秘钥以及地址

修改参数
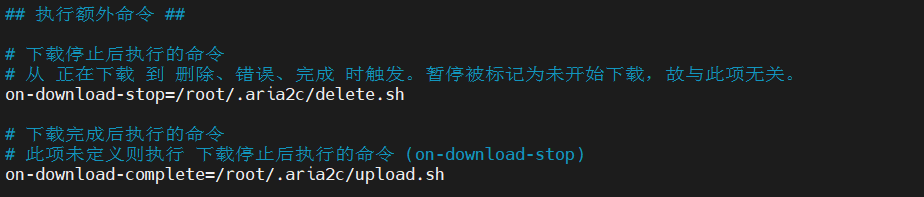
修改/root/.aria2c/aria2.conf中的on-download-complete参数的clean.sh为upload.sh,用于下载完成后的自动上传
替换命令:
sed -i 's/clean.sh/upload.sh/g' .aria2c/aria2.conf
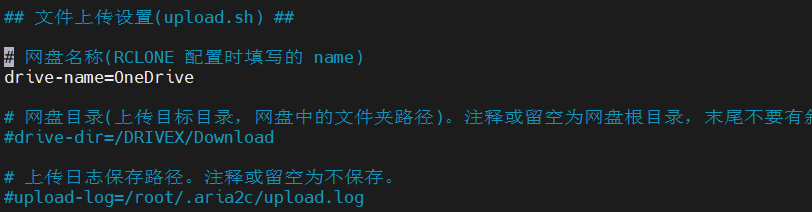
修改script.conf中的网盘名称(你知道我为啥刚才给Google Drive取名叫OneDrive了吧。。)
搭建VPS上的Radarr(非必须)
docker-compose.yaml文件:
version: "3"
services:
radarr:
image: linuxserver/radarr:version-4.1.0.6175
container_name: radarr
environment:
- PUID=0
- PGID=0
- TZ=Asia/Shanghai
volumes:
- /root/docker_config/radarr:/config
- /root/downloads:/downloads
ports:
- 7878:7878
restart: unless-stopped
使用方法
打开本地/远端Radarr,添加Aria2下载器,host填写VPS的ip地址,Secret Token填写Aira2的秘钥
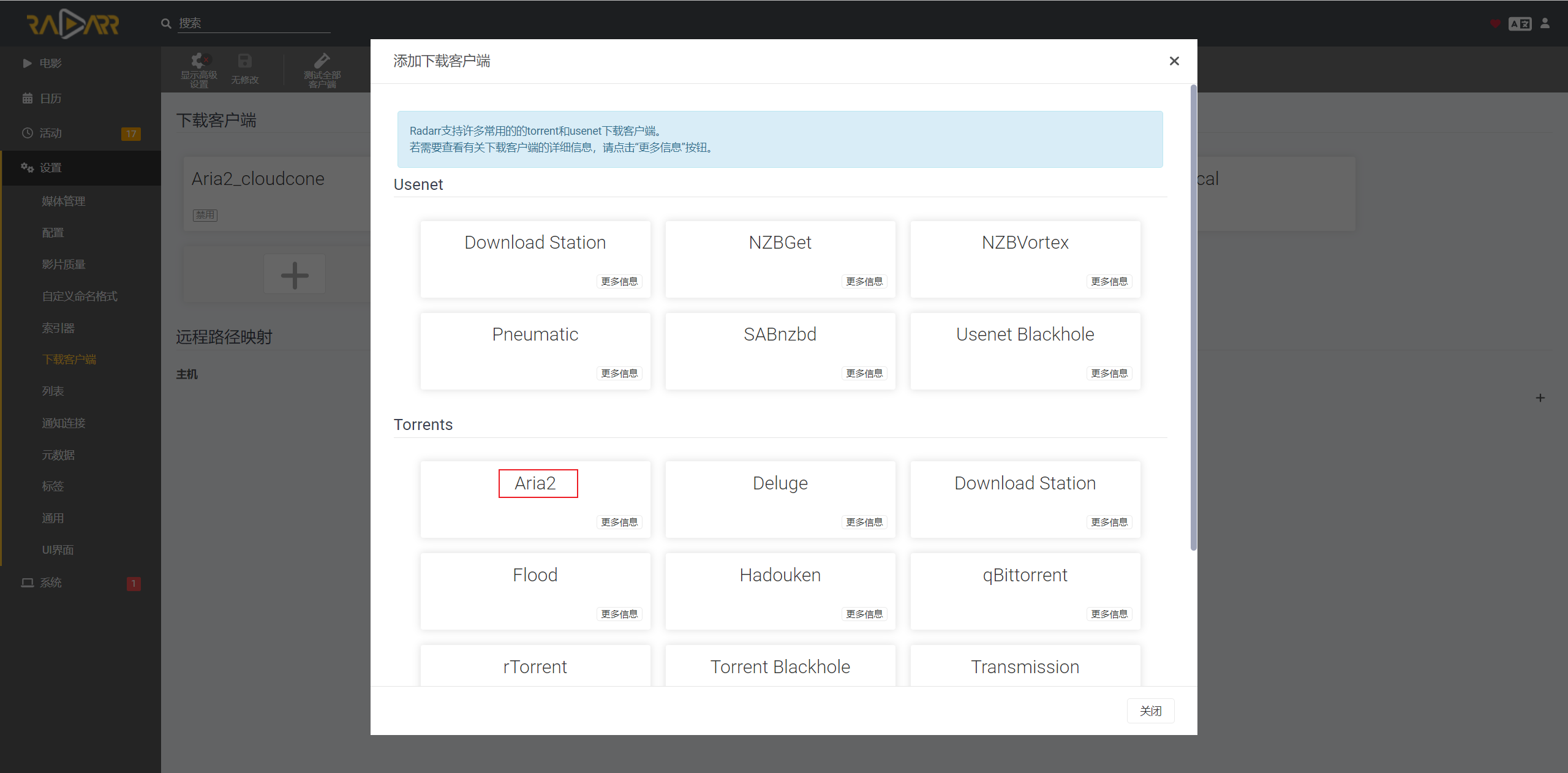
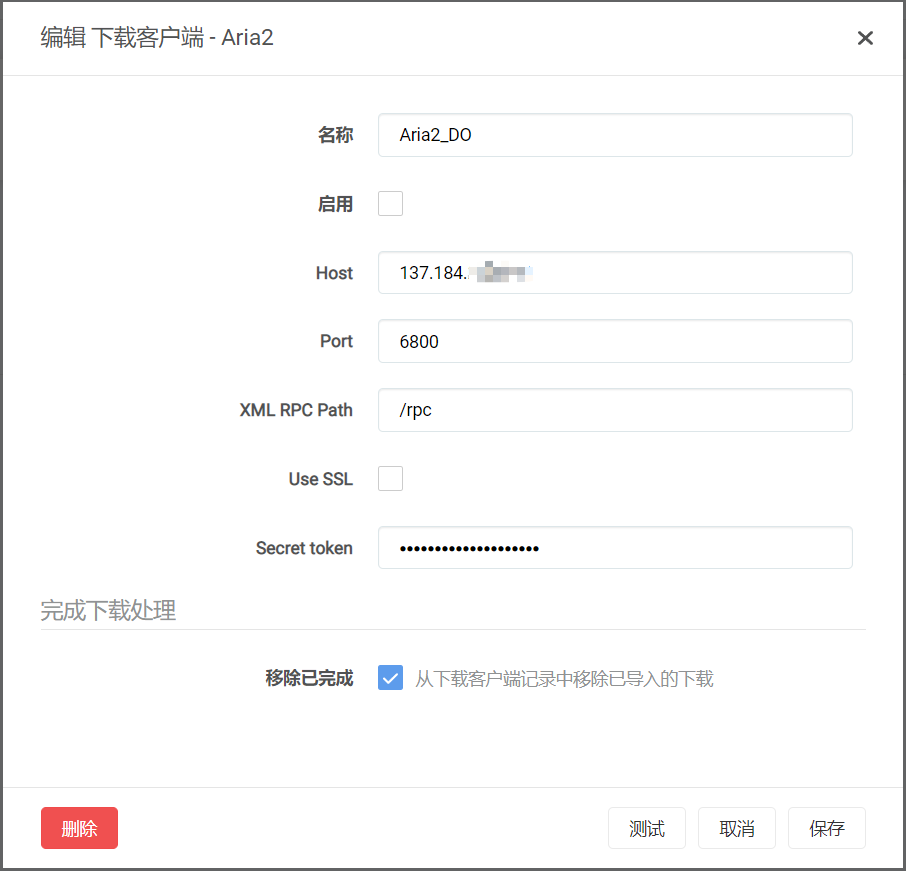
然后就可以在Radarr里面愉快地下电影了。
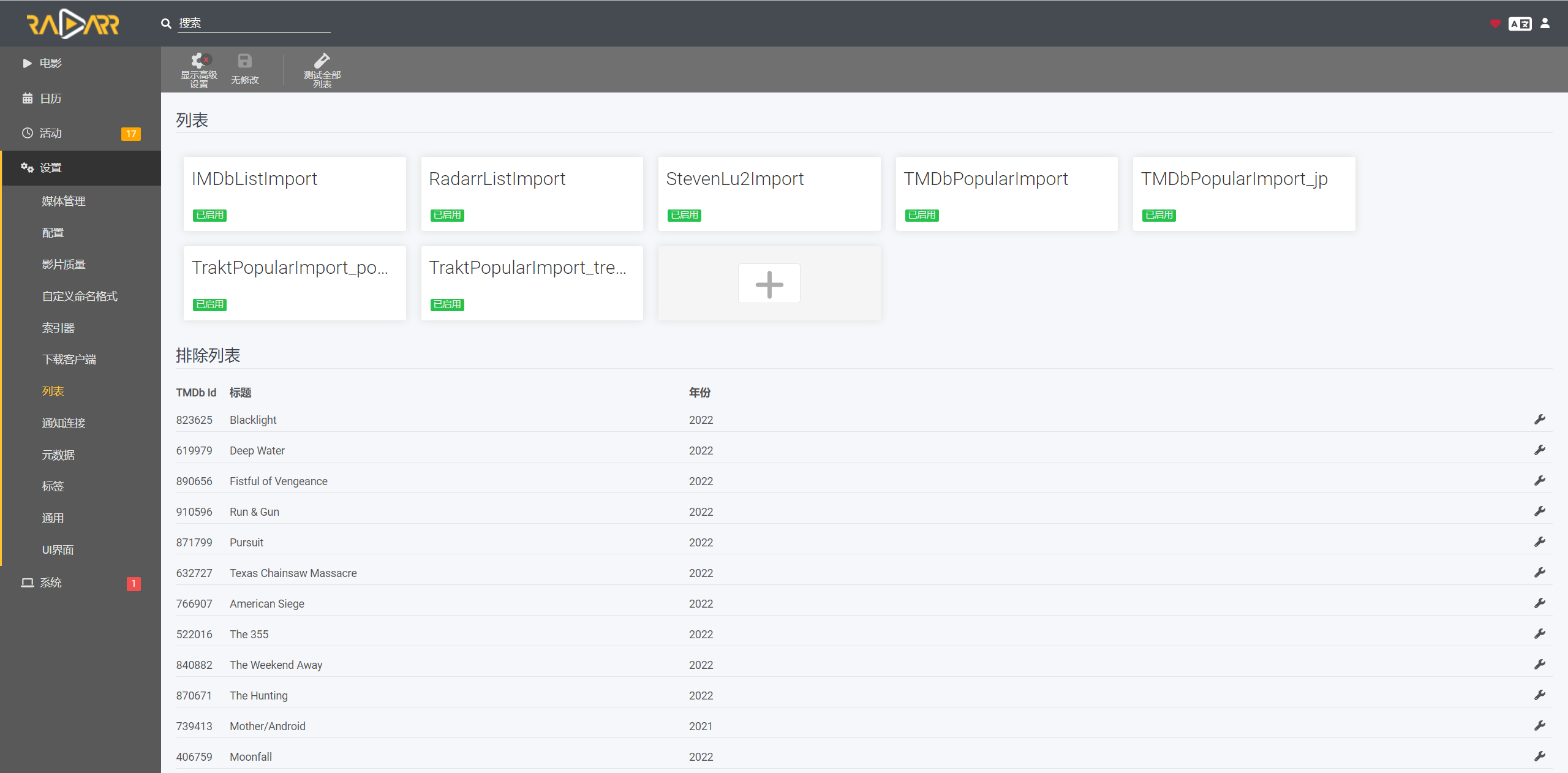
我喜欢通过列表(Lists)下电影,先在列表里面添加几个地址
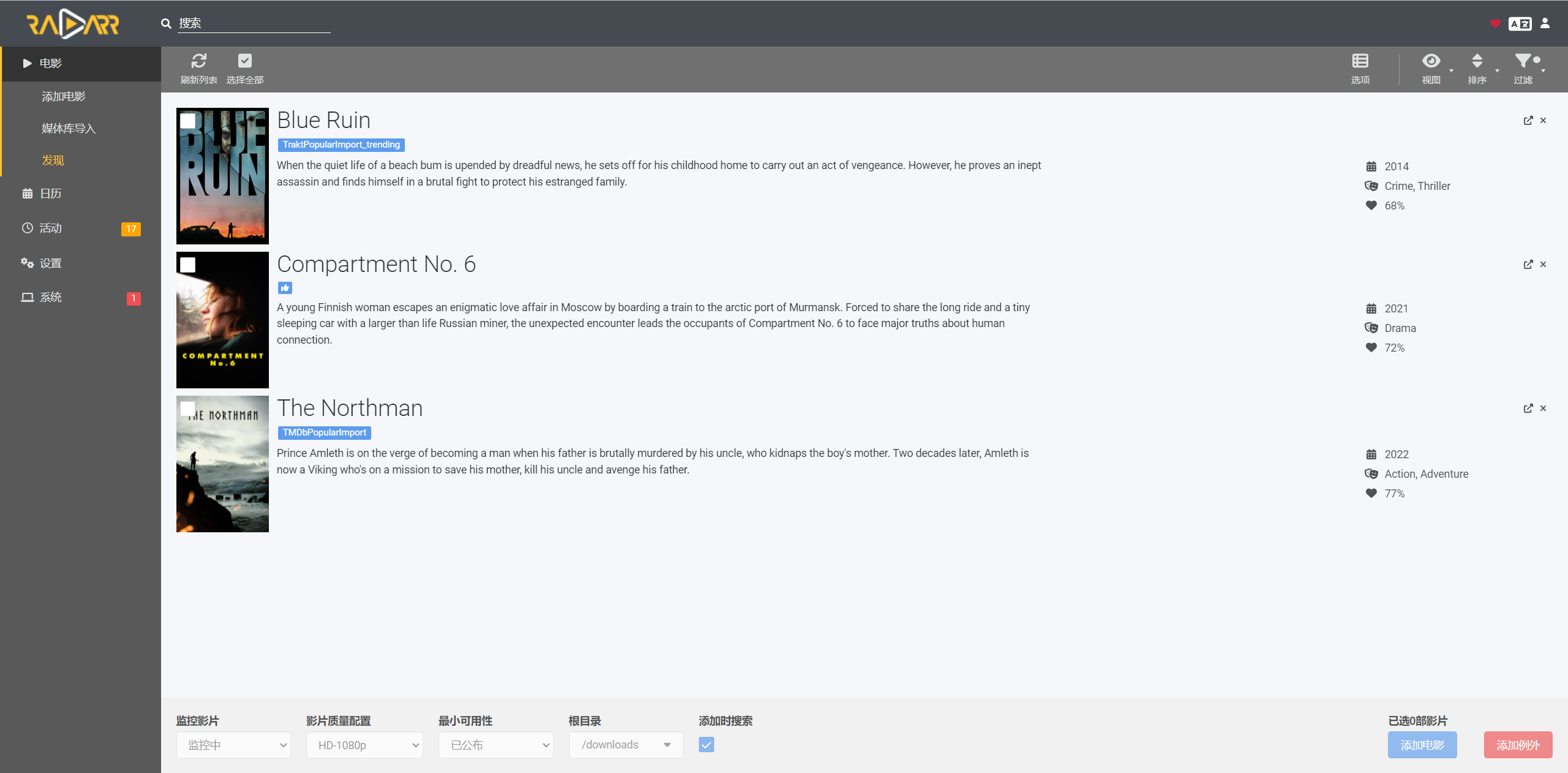
然后就可以通过发现搜索到了
从离线网盘拉取电影到本地
用https://github.com/Achrou/goindex-theme-acrou搭建goindex,获取直链,然后本地下载。
我写了个python脚本,脚本中的axel用于多线程下载,通过apt install axel安装。
from socket import timeout
import subprocess
import requests
import json
import os
import time
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
source_url = 'http://drive.aria2c.gq/3:/' # 修改为你的goindex地址
dest_path = '/root/downloads3' # 修改为本地的电影下载目录
retry_strategy = Retry(
total=5,
status_forcelist=[429, 500, 502, 503, 504],
allowed_methods=["HEAD", "GET", "OPTIONS"]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
http = requests.Session()
http.mount("https://", adapter)
http.mount("http://", adapter)
def find_film(files):
suffix = ('mkv', 'mp4', 'rmvb', 'mov', 'flv', 'wmv', 'avi')
for file in files:
if file['name'].endswith(suffix):
return file['name'], int(file['size'])
def get_url(url):
cookies = {
xxxxxxxxxxxxxx
}
headers = {
xxxxxx
}
json_data = {
'q': '',
'password': None,
'page_token': None,
'page_index': 0,
}
response = http.post(url, headers=headers, cookies=cookies, json=json_data, verify=False, timeout=5)
return response
def run(downloaded):
url = source_url
response = get_url(url)
files = json.loads(response.text)['data']['files']
file_url_list = []
for file in files:
filename = file['name']
if filename in downloaded:
continue
file_url = url + filename + '/'
file_url_list.append((file_url, filename))
cnt = 0
for file_url, directory_name in file_url_list:
while True:
try:
res = get_url(file_url)
files = json.loads(res.text)['data']['files']
break
except InterruptedError:
exit(0)
except:
continue
filename, suppose_filesize = find_film(files)
filename_url = file_url + filename
real_filesize = 0
if os.path.exists(f'{dest_path}/{directory_name}/{filename}'):
real_filesize = os.path.getsize(f'{dest_path}/{directory_name}/{filename}')
print(directory_name)
if real_filesize == suppose_filesize:
print('文件已下载,跳过')
downloaded.add(directory_name)
json.dump(list(downloaded), open('downloaded', 'w'))
continue
else:
print('文件大小不匹配,重新下载')
# subprocess.run(f'rm -rf {dest_path}/{directory_name}', shell=True)
filename_url = filename_url.replace("'","\'")
subprocess.run(f'mkdir "{dest_path}/{directory_name}"', shell=True)
subprocess.run(f'axel -n 30 "{filename_url}" -o "{dest_path}/{directory_name}/{filename}"', shell=True)
cnt += 1
if cnt == 0:
print('all done, wait 1h')
time.sleep(3600)
# exit(0)
if __name__ == '__main__':
while True:
try:
downloaded = json.load(open('downloaded', 'a'))
downloaded = set(downloaded)
run(downloaded)
except Exception as e:
print(str(e))
time.sleep(1)
pass
然后改下cookie,抓个包复制为cURL(bash),到https://curlconverter.com/,转换为python代码
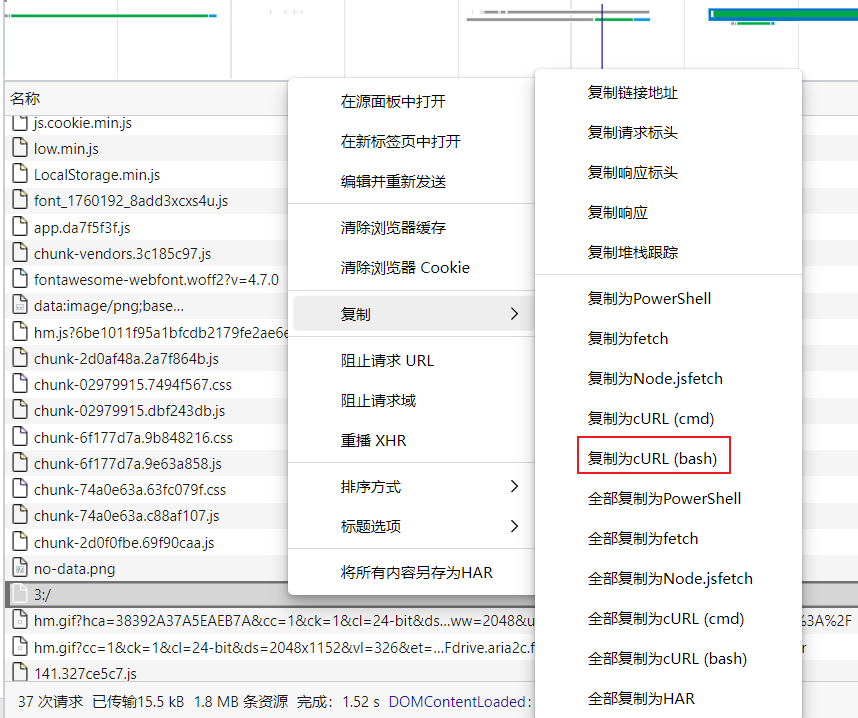
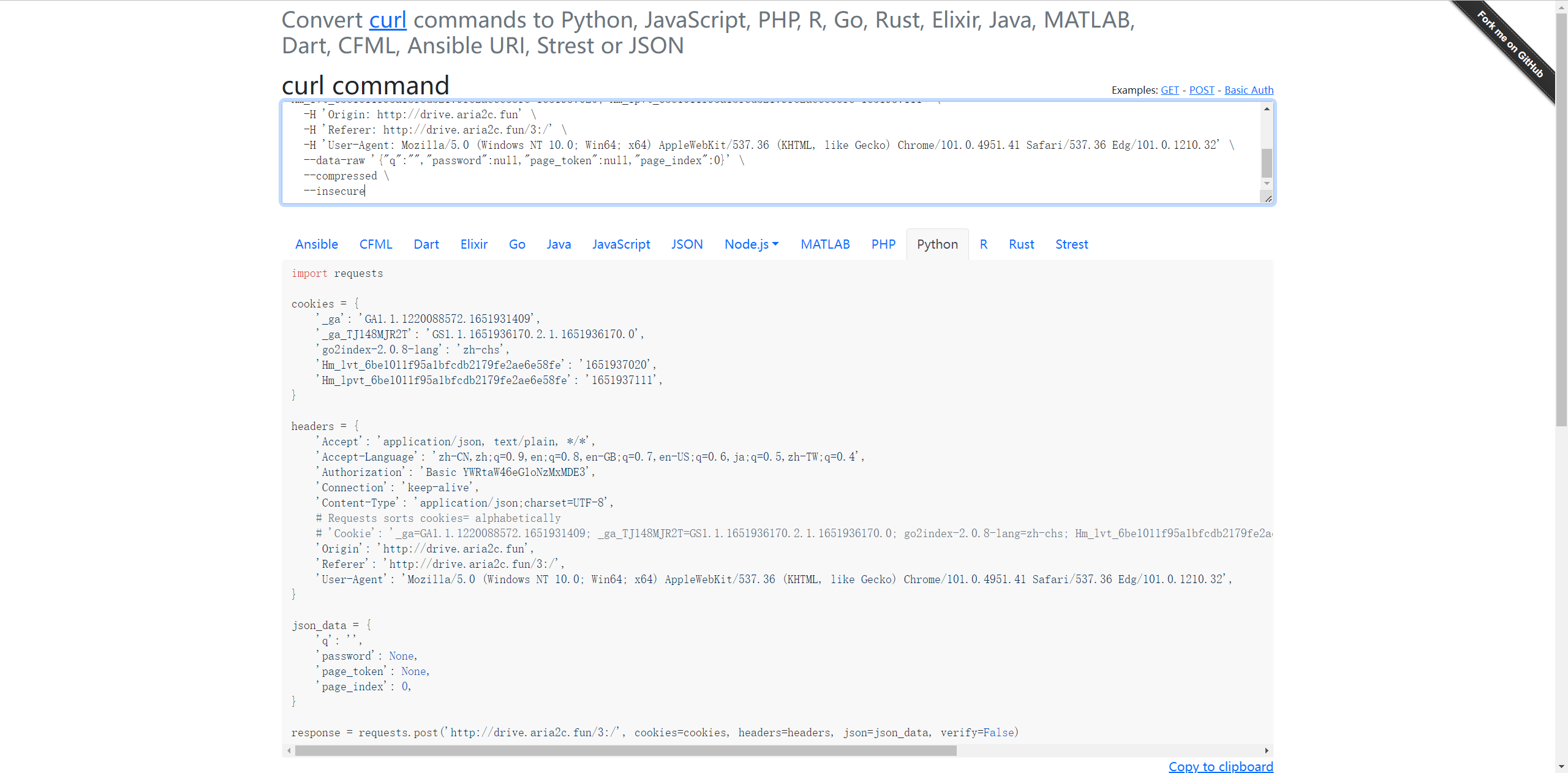
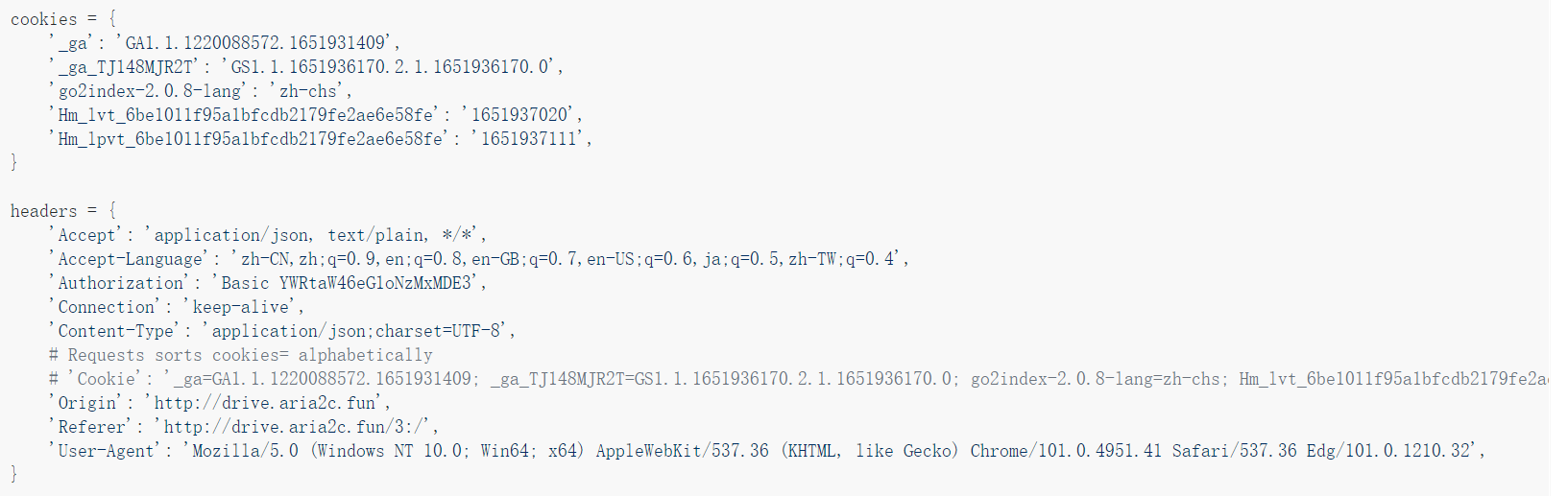
cookies和headers替换掉上文中的xxxxxxx
评论区